首先总结一下计算机中的浮点数的存储。
浮点数的标准是IEEE-754,规定了浮点数的存储都是通过科学计算法来存储的,n2-e的表示。
浮点数首先分为,定浮点(fixed-point)和浮点(float-point),定浮点就是说e的值是不变的。
目前浮点的计算都是将浮点转换为定浮点来计算,由此衍生出,单精度浮点和双精度浮点。
浮点数的存储,前半部分表示exponent(可以是负数,使用补码表示),后半部分表示fraction(规定fraction必须是1.x的格式)。
单精度的储存位宽是32bit,e占7bit,最大表示-62---63,fraction占23bit。
双精度的存储位宽是64bit,e占10bit,最大表示-510---511,fraction占52bit。
比如1.01 X 2-3,其中exponent表示-3,.01表示fraction。
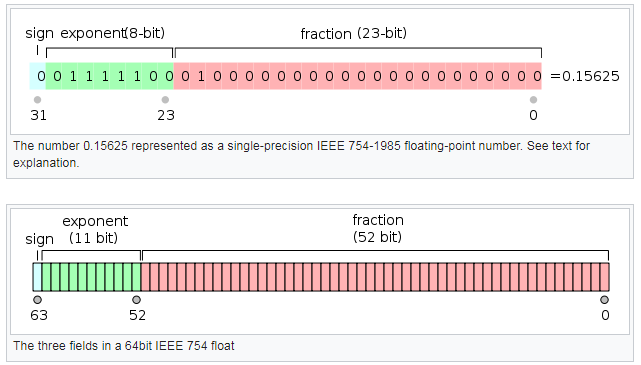
单精度和双精度的,精度对比:

浮点数的规则化(normalized):
fraction必须是|1.x|的格式;
非规则化的数:
正零:所有bit都为0;
负零:除了符号位,都为0;
无穷大:exponent的所有bit都为1;fraction的所有值都为0;
负无穷大:exponent的所有bit都为1;fraction的所有值都为0,符号位为1;
非法数值:exponent的所有bit都为1;fraction的值不全为0;NaN(Not a Number)
浮点数的计算:
1)判断是否有操作数为0;
2)对阶:小阶向大阶对齐,阶小的那个数(看正负),exponent加n,fraction右移n位。
3)加减运算,fraction做加减运算,exponent不变。
4)结果规格化。(这时会有舍入处理,IEEE754规定了几种舍入)
判断溢出,浮点只有exponent的上溢,(正数相加不为负,负数相加不为正);
加减:
![]()
乘法:
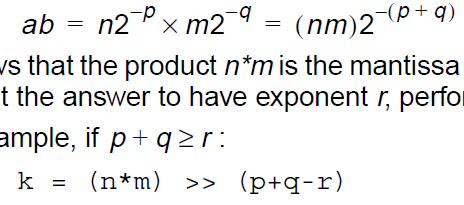
除法:

平方根:
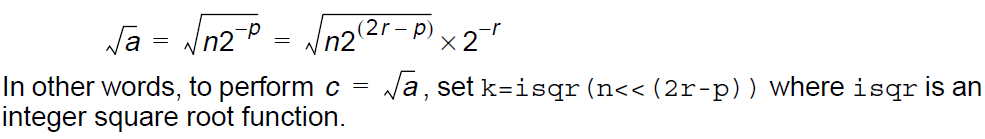
Basic op:


arm的SIMD指令的发展:
SIMD,一般应用在数据量较大的场合,使用一条指令,加载多个同样type和size的数据,并对数据进行并行处理;
例如,2个32bit的数据加法,被替换为,4个8bit的数据加法。
armv6,提出一些SIMD的指令,将多个16bit,8bit的数据加载到32bit寄存器中,但是并没有单独的执行单元,
也没有单独的流水线。指令名字就是在之后加16或8的后缀。
armv7,引入了advanced SIMD,定义了自己的向量寄存器,自己的流水线执行单元。这些SIMD的扩展被称为NEON。
向量寄存器,是一组64bit的双字,或28bit的四字,
NEON指令可以实现:
1) 存储空间访问;
2) 在NEON和general寄存器之间的数据copy;
3) 数据类型转换;
4) 数据计算;支持8bit,16bit,32bit,64bit的符号数整型,32bit/16bit的单精度浮点,
NEON指令:
VADD.I16 q0, q1, q2,表示使用8个16bit的并行加,
VMULL.S16, Q0, D2, D3,表示使用4个16bit的并行乘,
NEON在使用gcc编译器时的选项:
1) 编译汇编,arm-none-linux-gnueabi-as -mfpu=neon asm.s
2) 关联函数intrinsics, #include <arm_neon.h>
uint32x4_t double_elements(uint32x4_t input)
{ return(vaddq_u32(input, input));
}
arm-none-linux-gnueabi-gcc -mfpu=neon intrinsic.c
3) 优先矢量化,arm-none-linux-gnueabi-gcc -mfpu=neon -ftree-vectorize -c vectorized.c
4) 使用优化库,OpenMAX,需要下载安装,程序中加入头文件,#include <omxSP.h>
VFP在使用时,与NEON的编程类似,寄存器一部分是共享的。
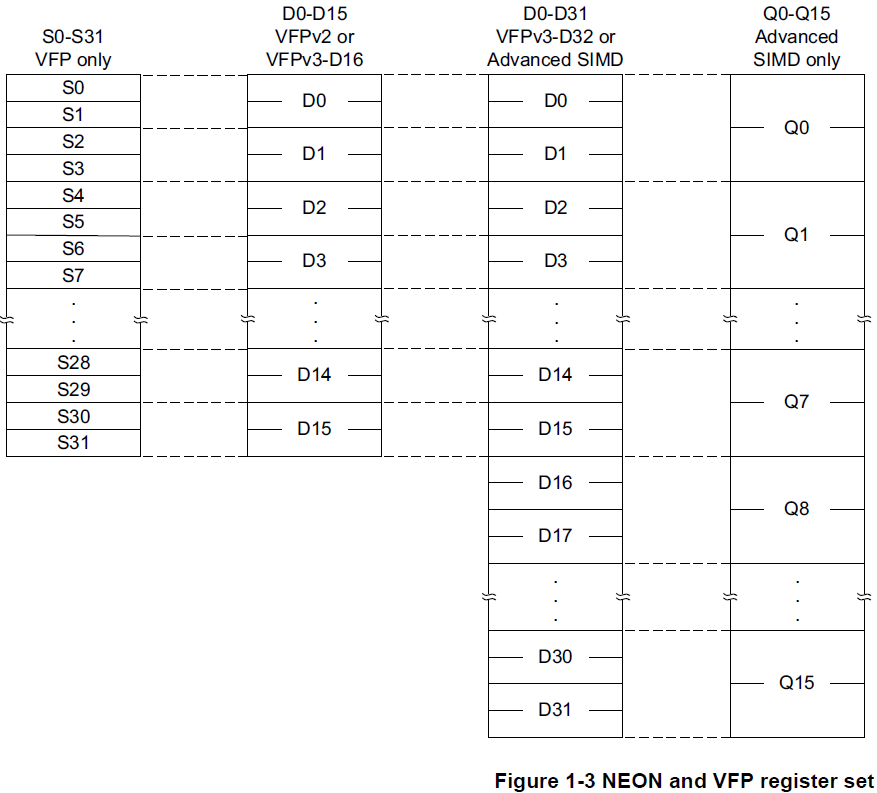
NEON与VFP的浮点计算对比:
1) NEON是SIMD指令,处理较多数据的效率高,并行度也高(最多是4)。
2) VFP支持全IEEE754的标准,NEON只支持单精度浮点。
gcc的选项,-mfpu = (neon/vfpvx) 指定FPU单元;
-mfloat-abi = (soft, hard, softfp)指定软件浮点,硬件浮点,兼容软浮点调用接口;